
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데스나이트 키우기 쿠폰 정리글
- 양재천 사진
- jwt 토큰 생성
- token provider 구현
- logstash 설정
- 스프링 security
- 해군
- 데스나이트 키우기 매크로 소스파일
- logstash cubrid 설정
- 퇴직 라이프
- 정보보호병
- 파이브 스타즈
- 코로나 19 견디기
- 정보보호병 프로그래밍
- jwts 토큰
- 양재천 오리
- 파이브 스타즈 후기
- 파이브 스타즈 사전예약
- spring boot token provider
- Jwts 토큰 만들기
- 파이썬
- 스프링 로그인 기능 만들기
- 데스나이트 키우기 매크로
- 양재천 장마 피해
- 데스나이트 키우기
- 정보보호병 개발
- 멀티 파이프 라인
- 토큰 만드는법
- 로그스태쉬
- 정보보호병 후기
- Today
- Total
InTen
[Python3.x ]Pandas 파이썬 CSV 불러오기와 데이터 간단 활용 예제 본문
Pandas란
Pandas는 파이썬에서 사용하는 데이터분석 라이브러리로, 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 되며 보다 안정적으로 대용량의 데이터들을 처리하는데 매우 편리한 도구 입니다.
Pandas 사용하기
일단 Pandas를 사용하기 전에 이번 글에서 무엇을 해볼건지 먼저 잡고 가겠습니다.
우리는 공기질 데이터를 입력 받아서 아래의 CSV 파일의 fromaqi 컬럼과 toaqi 컬럼 사이의 공기질 데이터를 도출해 description 컬럼을 노출할 것 입니다.
아래는 한국의 공기질 데이터 분류 엑셀 데이터 입니다.

전체 코드를 보여드리겠습니다.
1 import pandas as pd
2 csv_test = pd.read_csv('C:\\Users\\kim\\Downloads\\aqi\_index.csv', encoding = 'EUC-KR')
3
4 pm_10, pm_25 = map(int,input("PM 10, PM 2.5 데이터 입력 : ").split())
5 print(csv_test)
6 pm_10_row = csv_test.loc[csv_test["pollutant"] == "PM10"]
7 pm_25_row = csv_test.loc[csv_test["pollutant"] == "PM2.5"]
8 print(pm_10_row)
9 print(pm_25_row)
10 pm_10_result = pm_10_row[(pm_10_row["fromaqi"] <= pm_10) & (pm_10_row["toaqi"] >= pm_10)]
11 pm_25_result = pm_25_row[(pm_25_row["fromaqi"] <= pm_25) & (pm_25_row["toaqi"] >= pm_25)]
12 print("PM 10 상태 : ", pm_10_result["description"])
13 print("PM 25 상태 : ", pm_25_result["description"])
위의 코드를 해석하자면 첫줄에선 pandas 라이브러리를 임포트를 하는 부분입니다.
Line 2는 CSV 데이터를 들고오는 코드 인데요. 여기서 옵션으로 encoding 옵션을 주었습니다. 이유는 csv파일이 utf-8로 되어 있어서 한글인코딩이 지원이 되지 않아 깨짐 문제가 발생해서 euc-kr 로 들고오게 되었습니다.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 0: invalid start byte이러한 오류가 뜨신다면 위의 encoding 옵션을 사용해주세요.
Line 5는 가져온 CSV 파일 전체를 출력하는 부분 입니다.

CSV 파일을 그대로 가져온 상태이며 왼쪽에는 인덱스가 추가가 되어서 붙습니다.
Line 6,7 은 loc 이라는 함수를 사용하게 됩니다. loc 함수를 간단히 설명하자면
loc인덱스 기준으로 행 데이터 읽기, iloc행 번호를 기준으로 행 데이터 읽기 라고 설명 할 수 있겠습니다.
이에 대한 자세한 설명과 활용은 다음 게시글에서 설명하겠습니다.
loc 함수를 사용해 pollutant 컬럼의 PM10의 기준 데이터와 PM2.5의 기준 데이터 컬럼을 2개의 테이블로 분리하는 코드 입니다.
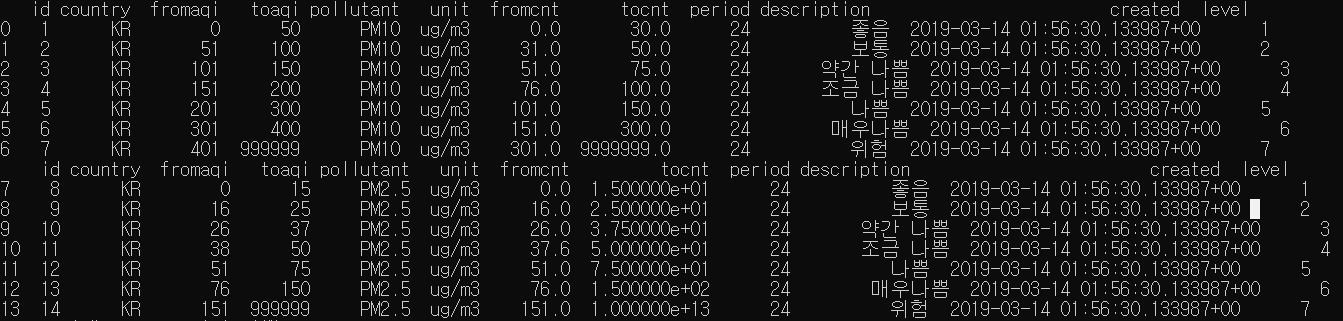
이렇게 2개의 테이블이 분리가 되어서 출력이 됩니다.
Line 10, 11 의 코드는 input으로 받은 PM10과 2.5 데이터를 fromaqi 와 toaqi 컬럼 사이의 행을 가져와서 각 result 변수에 담는 부분입니다.
& 연산을 사용하기 위에 각 연산 관계를 ()로 묶어준뒤 &를 사용해 데이터 행을 가져오고
print 함수에서 그 행에 맞는 description 컬럼을 출력해주면 아래와 같은 결과를 얻게 됩니다.

이것 처럼 pandas를 사용하면 여러가지 CSV 데이터를 가져와 분석, 활용을 할 수 있게됩니다.
다음 글에서는 loc, iloc 사용법과 차이점에 대해서 기술하겠습니다.
감사합니다.
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [Python 3.x] 파이썬 다운로드 설치 & 환경 변수 세팅 (0) | 2020.08.28 |
|---|---|
| [Python 3.x] 파이썬 소수 구하기 (1) | 2020.08.28 |
| [Python 3.x]파이썬 별찍기 모든 종류 정리 숙련,초급 단계 포함 (0) | 2020.08.27 |
| 파이썬 2차원 배열 input 쉽게 하기 (0) | 2016.09.02 |
| 파이썬을 이용한 세이브 게임 만들기 (0) | 2016.03.09 |


